ich habe ein kleines Problem bzw. ein nice to have Wunsch
ich möchte gerne die Vertretungsstunden unsere Gemeinschaftsschule in IPS bringen und im Webfront darstellen. Wir müßten sonst jeden Tag vor der Schule online gehen und auf den Plan gucken. URL Vertretungsplan http://sgs.bbzsl.eu/Internet-heute/subst_001.htm
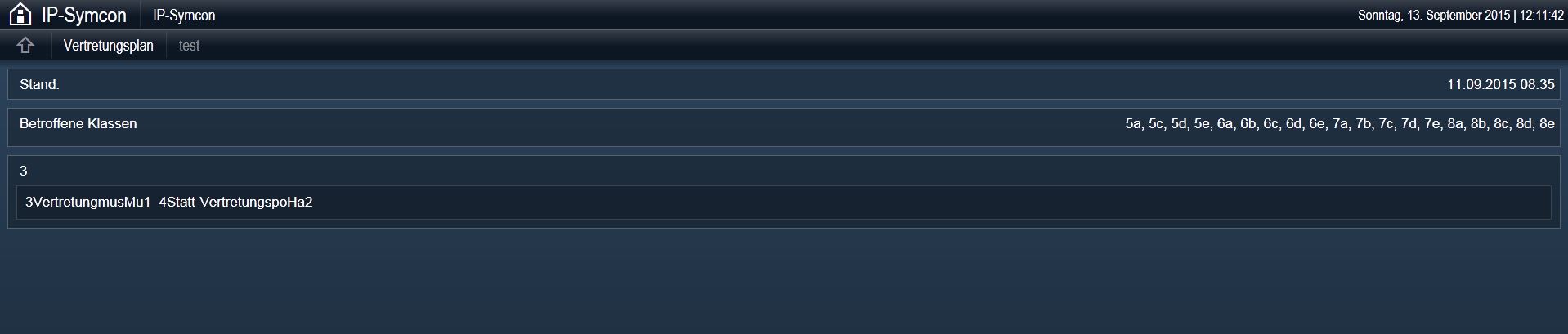
Ich habe es hingekommen, dass mir im Webfront der Stand: (Datum) angezeigt wird und die Klassen, die von der Vertretung betroffen sind werden auch als StringVar angezeigt. Auch der Textparser schneidet mir den Text raus. z.B 3VertretungMusMu1 , wobei die 3 die Stunde ist / Vertretung ist die Art/ Mus das Fach/ Mu1 der Raum… alles zusammenhängend. Wie bekomme ich das auseinander als Tabellenform so wie es auf der Seite der Schule ist?
Danke für deine Hilfe mit dem Dom X Path. Ist absolutes Neuland für mich. Ich verstehe nicht wie das Copy X Path mir nur die Vertretungsstunden der 5A raussucht. Die 5A könnte auch woanders in der Liste stehen, ist kein muß das es am Anfang steht.
Hab das Skript nun so verändern, von umbau kann man nicht wirklich reden.
Skript sieht bis jetzt so aus:
<?
//error_reporting(E_ERROR | E_WARNING | E_PARSE);
$curl = curl_init('http://sgs.bbzsl.eu/Internet-heute/subst_001.htm');
curl_setopt($curl, CURLOPT_RETURNTRANSFER, TRUE);
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, 0);
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, 0);
curl_setopt($curl, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13');
$page = curl_exec($curl);
//print_r($page);
if(curl_errno($curl)) // Error-Check
{
echo 'Scraper error: ' . curl_error($curl);
exit;
}
curl_close($curl);
$DOM = new DOMDocument;
//print_r($DOM);
libxml_use_internal_errors(true);
if (!$DOM->loadHTML($page))
{
$errors="";
foreach (libxml_get_errors() as $error) {
$errors.=$error->message."<br/>";
}
libxml_clear_errors();
print "libxml errors:<br>$errors";
return;
}
$xpath = new DOMXPath($DOM);
//print_r($DOM);
// Anzahl der Themen im IPS Forum unter "Neugikeiten & Ankündigungen"
$content = $xpath->query('/html/body/center[1]/p[1]/table/tbody/tr[2]/td');
foreach ($content as $entry1) {
$output[] = $entry1->nodeValue;
}
//print_r($output[1]);
// Wegschneiden von unnötigen Zeichen
//preg_match_all('!\d+!', $entry1->nodeValue, $matches);
// Ausgabe
//$output_final = $matches[0][0];
//echo "Anzahl der Themen: $output_final";
//print_r($output_final);
?>
Verstehe leider die Ausgabe auch nicht, es fehlt eine Variable??? Sicherlich eine VAR als HTML_Box aber wie bekomme ich die in das Skript. Habe es auch mit deinem Synology Skript versucht, aber auch das ist zu hoch für mich.
Vielleicht nehme ich mir die ganze Seite als HTML Box und schicke mir dann bei Neueintragungen eine Nachricht aufs Smartphone.
Wenn man nur die Vertretungen einer Klasse (z.B. 5a) auslesen möchte, dann wird es etwas umständlicher, weil an der Stelle das HTML etwas „unsauber/unschön“ geschrieben ist. Da gibt es keine klare Trennung und man muss von einer Klasse auslesen bis zur nächsten Klasse. Mal dem Ersteller der Seite auf die Finger klopfen
Man kann nicht einfach „Sub-Zweige“ auslesen. Aber mit ein wenig Gefummel ist es auch machbar
Darauf kannst du zumindest schon mal weiter aufbauen Das Skript z.B. einfach zu einer bestimmten Zeit ausführen und wenn in diesem Array der String „5a“ enthalten ist, dann weißt du, dass es Vertretungsstunden für die 5a gibt und du kannst dir z.B. eine Push-Nachricht schicken lassen. Dann entweder die Seite einfach aufrufen und nachschauen, oder noch etwas Arbeit investieren und die Vertretungsstunden auch noch auslesen.