Das gibt es noch ![]()
Muss hier auch dringend sortieren.
Danke für den Tip mit immich , werde ich mir dann auch mal anschauen.
Ähnlicher Aufbau → Docker und einer Ubuntu VM + Windows Server VM als FileServer auf dem gleichen Blech.
Michael
Ich hab in der fstab den mount eingebaut. Aber ohne Credential file ![]()
Im Portainer habe ich den Eintrag bei volumes hinzugefügt (/media/bilder)
name: immich
services:
immich-server:
container_name: immich_server
image: ghcr.io/immich-app/immich-server:${IMMICH_VERSION:-release}
# extends:
# file: hwaccel.transcoding.yml
# service: cpu # set to one of [nvenc, quicksync, rkmpp, vaapi, vaapi-wsl] for accelerated transcoding
volumes:
# Do not edit the next line. If you want to change the media storage location on your system, edit the value of UPLOAD_LOCATION in the .env file
- ${UPLOAD_LOCATION}:/usr/src/app/upload
- /etc/localtime:/etc/localtime:ro
- /media/bilder:/media/bilder:ro
In immich bei den Externen Bibliotheken den Pfad /media/bilder eingetragen. Das tut jetzt bei mir.
Auf jeden Fall Excire Foto. Das ist für mich die beste KI Lösung in dem Bereich und preislich auch im Rahmen.
Nutze ich zudem als Excire Search in Lightroom privat als auch beruflich als Fotograf.
ACDSEE
Klar gibt’s das noch. Inzwischen kostenpflichtig aber immer noch gut.
Der Vertrieb nervt ein wenig wegen Updates - naja, Amis halt.
Ich habe auch Exire Foto seit ein paar Jahren im Einsatz und finde die KI schon sehr hilfreich.
Anfangs tendierte ich dazu, meine Datenbanken thematisch aufzuteilen, was sich aber nicht wirklich bewährte.
Mittlerweile habe ich eine große Datenbank und lasse die KI suchen.
Aber ehrlicherweise kenne ich keine KI, die nicht zusätzlich Arbeit macht, die man ohne sie nicht hätte.
Etwas enttäuscht bin ich von der Gesichtersuche. Das kann jedes iPhone von Haus aus besser.
Die Ergebnisse sind zu ungenau und somit muss ich über Stichworte nachhelfen, was wieder in Richtung manuelles Bearbeiten geht.
Man sollte auf Rabattaktionen achten.
Gruß
Andreas
bin schon ziemlich lange bei immich.app und lasse es in meine Proxmox-Cluster mitlaufen.
Die KI ist schon recht gut und hat sich in den letzten Monaten extrem verbessert - ich denke das Ende ist noch nicht erreicht.
Leider ist die „einfachste“ Installation tatsächlich über Docker, ich hätte es lieber direkt unter Debian/Ubuntu laufen, habe es aber irgendwie nie geschafft es genau so performant laufen zu lassen wie mit Hilfe des Docker-Containers.
Dann probier mal Immich, du wirst dich wundern was da heute schon so möglich ist.
Fairerweise muß man aber sagen das die AI Sachen das einzig gute an dem Program sind. Alle anderen für Galleryprogramme typischen Features sind entweder nicht oder nur sehr rudimentär vorhanden. Da haben die Jungs schon noch Arbeit vor sich wenns dauerhaft bestehen wollen.
greez
bb
Moin Bernhard, ich beschäftige mich schon länger mit dem Thema und nutze einige professionelle Programme verschiedenster Gebiete mit AI. Mittlere vierstellige Euros habe ich bereits privat investiert. ![]()
Gerade bin ich wieder dabei, meine gefühlt 5 Billionen Bilder vernünftig einzuordnen. Aktuell mit Excire und mit Unterstützung von anderen Tools.
GraphicConverter von Lemke Software hat mittlerweile auch eine wirklich gute Erkennung und vergibt brauchbare Stichwörter.
Trotzdem tauchen bei allen AI Tools immer wieder Stichworte auf, die gar nicht passen und man sich fragt, wie man darauf kommt.
Lightroom I.V.m. Excire wäre ein Dreamteam, wenn ich die Preispolitik von Adobe nicht ablehnen würde. Lightroom hab ich noch als unabhängige Classic Version aber habs dann aufgegeben.
Auf etwas Ähnliches von Affinity warten viele Nutzer schon ewig.
Mit Luminar bin ich durch.
Aber auch ein nettes Beispiel, was KI mittlerweile kann und nicht kann.
Auf Knopfdruck geht da Einiges aber wenn Du Dir die Übergänge anschaust, wird’s gruselig.
Das Ergebnis kenne ich auch von ChatGPT, wenn es Bilder erfindet. Der Wow Effekt ist doch nur bei oberflächlicher Betrachtung vorhanden und relativiert sich doch sehr bei genauerer Betrachtung.
Ja, es wird besser aber meine Begeisterung hat sich mittlerweile gelegt. Es gibt Probleme, die löst die KI richtig gut. Geht man ins Detail, dann erkennt man schnell die Schwächen. Grob würde ich sagen, dass alles, was dem Menschen schwer fällt, meistert sie spielend und bei Problemen, die für uns leicht sind, ist die KI schwach.
Gutes Beispiel ist auch das autonome Fahren. Nach der anfänglichen Euphorie ist man mittlerweile doch in der Realität angekommen.
Einparken in allen Varianten oder im außerstädtischen Verkehr mitschwimmen ist halt ne andere Nummer, als in der Stadt zu erkennen, ob der Fußgänger nur am Bürgersteig steht oder vielleicht gerade doch auf die Straße laufen wird. Da sind unsere menschlichen Systeme doch deutlich überlegener.
Interessant auch immer, wenn Du Dir einen Text erstellen lässt und die AI Dinge einfach erfindet. Das passiert nicht selten und so musst Du alles genau durch lesen und recherchieren, was oft mehr Arbeit macht, als es selbst zu schreiben.
Meine Große ist gerade im Abitur und auch die Kids haben erkannt, dass die schnell mit ChatGPT erstellten Lösungen nicht der Heilsbringer sind.
Spätestens wenn die Lehrer dann schmunzelnd das teils absurde Ergebnis der Klasse vorstellen.
Auch die von Spark erstellten EMailtexte sind oft sehr unterhaltsam bis peinlich.
Nee, ich bin noch interessiert aber meine Erwartungen musste ich absenken.
Mein digitales Büro mit DEVONthink und Dokumentenscanner hinkt auch immer noch der Idee hinterher.
LG
Andreas
Ja, grundsätzlich hast du recht.
Das Problem ist das die Ergebnisse nur bis zu einer bestimmten Wahrscheinlichkeit korrekt sind. Für automatische Verschlagwortung mußt du aber eine harte Linie ziehen ob ein Tag nun bei xx% gesetzt wird oder nicht. Zusätzlich braucht es dann bestimmte Tag- Listen welche ggfl. nicht mit deinen Vorstellungen übereinstimmen.
Das klappt in der Tat nicht gut, auch nicht bei kostenpflichtigen Cloud Anbietern.
Subjektiv viel besser ist es wenn gar keine fixen Tags erstellt werden, sondern die Suche in Echtzeit läuft. So wie bei der großen Suchmaschine. Die Ergebnisse werden nach Trefferwahrscheinlichkeit sortiert als Liste ausgegeben. So kannst im du immer als Mensch für jede Suche extra entscheiden welche der gefundenen Ergebnisse dem gewünschten entsprechen oder eben nicht. Das „weiter unten“ nur mehr Müll kommt stört so nicht.
Subjektiv ist das mehr als ausrechend und sogar beängstigend wie gut das geht.
Aber natürlich gibts auch hier lustige Ergebnisse. Kürzlich hatte ich meinen Fundus nach „Programierer“ durchsuchen lassen. Ganz hoch geranked wurde ein Bild meiner Tochter als sie im Krabbelalter an einem zerlegten PV Gehäuse rumspielt. ![]() Wäre das als tag vergeben worden wärs unbrauchbar, einfach nur so als Suchergebniss isses witzig.
Wäre das als tag vergeben worden wärs unbrauchbar, einfach nur so als Suchergebniss isses witzig.
Oder als ich nach „Manager“ suchte: Gut das Ding bringt mir einige Bilder von diversen Hochzeiten (Männer im Anzug) aber auch ganz hochgerankt ein Foto das ich mal machte als mal ein Kollege am Schreibtisch eingeschlafen war … - ohne Worte -
OT: Allgemein finde ich diesen AI Hype aber absolut übertrieben. Kannst ja bald nichtmal mehr ein Packerl Milch kaufen ohne das AI dazukriegst. Ungefähr so wie es vor einigen Jahren mit Blockchain war. Gleiches Theater.
Lästig wirds nur wenn die Chefs drauf anspringen und sagen: Ja mach das Program doch mit Chat-GPT geht ganz toll habs selbst schon probiert.
Na sehr super, nie im Leben würde ich auch nur eine Zeile in meinen Programmen verwenden die ich nicht selbst 100% tig verstehen und dahinter stehen kann. Du weißt, ich erstelle Prüfkonzepte&Programme für sicherheitskritische Automotivkomponenten - oder möchte jemand das über die Qualität des ABS/Airbag Sensor in seinem Auto per Chat Dingsbums freigegeben wird ?
Nein nein, manchmal ist AI ganz lustig, aber das war es dann auch schon. Sobald harte Ja/nein Entscheidungen notwendig werden Finger weg.
greez
bb
1 „Gefällt mir“
Ein kleines Update nach ein paar Tagen mit „immich“.
Die Indizierung ist fertig. Sind nur etwa 21.000 Bilder. Das ganze hat etwa fünf Tage gebraucht. Wobei ich sagen muss, die VM auf dem Docker läuft hat minimalistische Ressourcen. 1GB RAM und 2vCPU’s. Die VM war ursprünglich als Gateway für meinen Deye Wechselrichter gedacht. Da läuft ein Image dafür. An den Einstellungen hab ich nichts geändert. Von daher hat der Wert von fünf Tagen eher wenig Aussagekraft. Sobald der Prozess beendet ist, läuft die Seite auch flüssig.
Die Gesichtserkennung funktioniert erstaunlich gut. Da bin ich echt beeindruckt. Es wurden auch gesichter richtig erkannt die auf Fotos im Hintergrund abgebildet sind. Sogar richtig. Das kommt sicher auch auf die Auflösung an.
Bei Begriffen bin ich mir noch nicht sicher. Muss ich da auf Deutsch oder Englisch suchen? Bei dem Suchbegriff „Hund“ werden nur zwei Fotos, aber Hund gefunden. Suche ich nach „Beagle“ dann bekomme ich sehr viele.
Alles in Allem finde ich es nicht schlecht.
![]() Sag ich ja, unglaublich - erschreckend - wie gut das mit den Gesichtern funktioniert. Jetzt stell dir mal vor da ist echt powerfull Hardware dahinter.
Sag ich ja, unglaublich - erschreckend - wie gut das mit den Gesichtern funktioniert. Jetzt stell dir mal vor da ist echt powerfull Hardware dahinter.
Das Default Modell ist für Englisch optimiert und kennt nur wenige Deutsche Begriffe. Für andere Sprachen mußt du eines der Multilingual Modelle nehmen. Allerdings sind die vieeeel größer und benötigen längere Rechenzeit.
Im Forum wurde da ein spezielles Modell empfohlen das zwar Englisch ist aber auch mit Deutsch gut klarkommt.
Den Namen des Modelles habe ich glaubich weiter oben gepostet.
Also mir reicht das vollkommen, die Suche geht dann fast gleich gut wie die Gesichtserkennung. 3 Tage Rechenzeit für 50k Bilder. Suche ca. 1-2 Sekunden. Auf alter Intel I5 Hardware. Du kannst damit auch nach ganzen Fragen suchen. Bspw. „weinendes Kind am Strand“ oder „volles Bierglas im Mondenschein“ oder „Mercedes im Regen“ funktioniert alles.
Kürzlich wurden noch weitere alternative ML Modelle supported. k.A. ob die noch besser sind. Aktuell reicht mir echtdas oben erwähnte. Umstellen auf andere Modelle bedeutet alles neu berechnen - da hab ich jetzt keine Lust um zu warten.
Übrigens gibst on der aktuellen CT ist auch ein Artikel über Immich. Aber schlecht getroffen wie ich finde.
viel Spass.
Bernhard
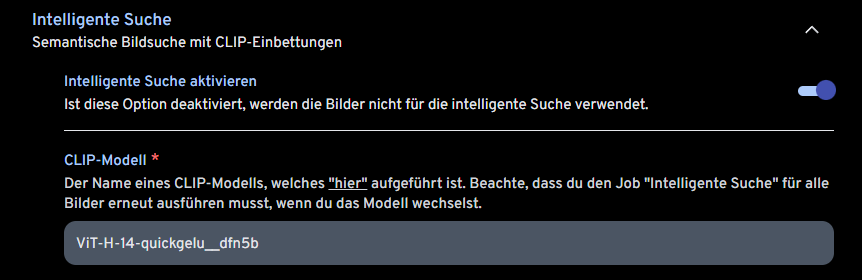
der korrekte Name lt. Immich ist:
immich-app/ViT-H-14-378-quickgelu__dfn5b
hier zu finden:
Hmm, ich hab das hier: ViT-H-14-quickgelu__dfn5b
Wenn ich die Nomenklatur richtig verstehe so ist das von dir verlinkte ein größeres Model. Damit ist es sicherlich auch besser aber auch deutlich rechenintensiver.
Leider dauert das indexieren bei meiner Archivgröße/Rechenleistung immer mehrere Tage da ist es etwas mühsam verschiedene Modelle durchzuprobieren.
Wie gesagt mit dem aktuellen Setting bin ich sehr zufrieden, wüßte jetzt nicht was da noch besser wünschen sollte.
Wenn man genug Rechenleistung spendiert und ggfls. eine entsprechende GPU, warum nicht. Das bessere ist der Feind des Guten.
Hast mal die aktuellen PullRequest gechecked ? Da sind grad einige Features in der Pipeline deren fehlen zzt. schon noch sehr schmerzt. Freue mich schon wenn die kommen.
greez
bb
Ok, Du und andere gaben den Tipp.
Beim Thema Familienalbum bin ich wieder darauf gestoßen und Immich kann da wirklich punkten.
Ich teste es gerade aus und habe es unter Docker auf dem NAS installiert.
So als Bilderalbum für die Familie, in das nur fertige katalogisierte, bearbeitete und sinnvolle Bilder zu Themen reinkommen.
Der Zugriff über App ist ja klasse.
Danke