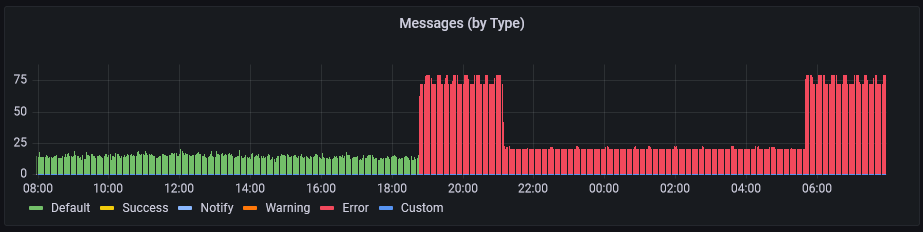
Der Einbruch in den späten Abendstunden und in der Nacht ist darauf zurückzuführen, dass dort weniger Daten per MQTT rein kommen.
Es sind ausschließlich Instanzen/Module betroffen, die direkt Daten von der MQTT-Server-Instanz erhalten.
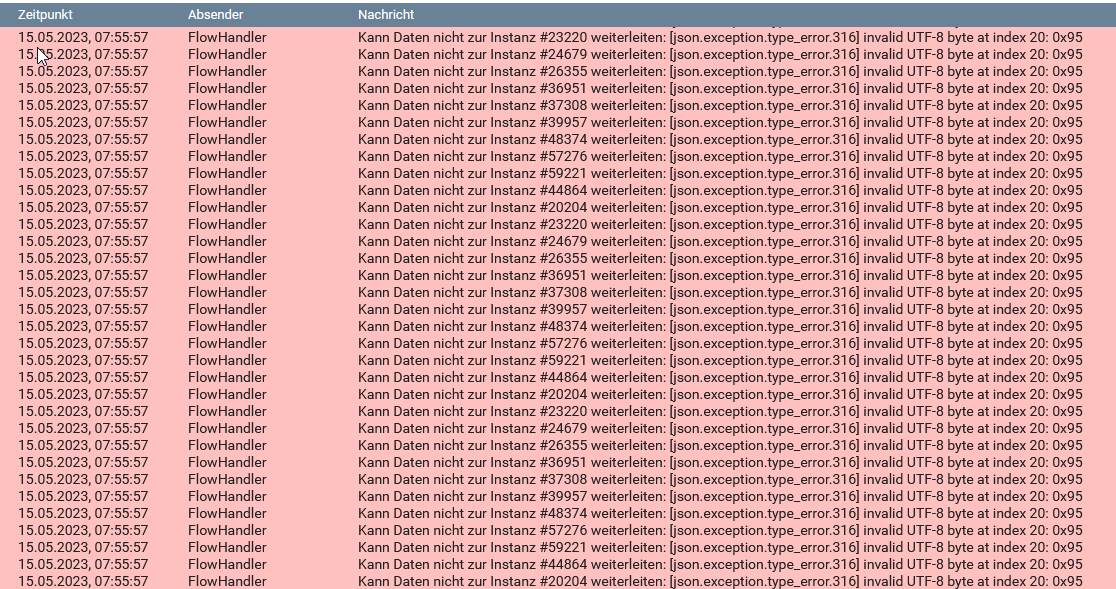
Das Konfigurationsformular der MQTT-Splitter-Instanz kann ich auch nicht mehr öffnen. Da kommt die gleiche Fehlermeldung. Die MQTT-Server-Device-Instanzen werden auch nicht mehr aktualisiert. Die Instanzen der anderen Module (die am Splitter hängen), zu denen ich die ganzen Fehlermeldungen sehe, erhalten aber interessanterweise ganz normal ihre Daten vom MQTT-Splitter.
Hat jemand eine Idee, was da plötzlich kaputt gegangen ist? Ich habe den Server noch nicht neu gestartet, da das meiste noch zu funktionieren scheint. Falls @paresy und Co. ggf. noch weitere Daten brauchen.
IP-Symcon 6.3, Windows (amd64), 09.02.2023, ce4bc83d8964
Ich würde es ja verstehen, wenn eine einzelne Instanz einen Fehler hätte. Dann hätte ich auch gesagt, dass von dem speziellen Gerät problematische Daten kommen. Aber wieso wird die Fehlermeldung zu allen möglichen Instanzen und Modulen angezeigt, obwohl diese ganz normal arbeiten und nur die MQTT-Device-Instanzen selbst versagen scheinbar ihren Dienst?
Ich würde jetzt mal behaupten, dass die meisten Module irgendeinen Filter für den Datenstrom benutzen. Dann dürften doch zu den Instanzen auch keine Fehlermeldung kommen, oder? Oder wird der Fehler pauschal für alle Instanzen ausgegeben, die an dem Splitter hängen?
Ich würde den Splitter ja Debuggen, um zu sehen, was da für Daten kommen. Aber ich kriege ihn ja nicht auf.
Ich habe den Datenverkehr vom MQTT Server Socket getraced und konnte so das problematische Gerät identifizieren. Durch einen Neustart des Gerätes sind die Daten wieder ok und die Fehler kommen nicht mehr.
Allerdings kann ich nach wie vor nicht das Konfigurationsformular der Splitter-Instanz öffnen. Da kommt weiterhin dieser Fehler:
Wieso? Das dürfte doch nichts mit fehlerhaften empfangenen Daten zu tun haben.
Bei MQTT gibt es ja Topics welche vorgehalten werden müssen wenn das retain flag gesetzt war.
Somit können da noch immer kaputte Daten im Speicher liegen.
Neustart vom Dienst hilft da.
Michael
Ist unterm Strich natürlich schon blöd, wenn korrupte Daten den ganzen Server durcheinander bringen. Wäre schön, wenn der Server diesbezüglich etwas robuster wäre. Sowas kann ja immer mal vorkommen.
Eigentlich haben wir dort in den letzten 6.3er Update einiges verbessert. Weißt du wo genau das defekte Paket die Zeichen drin hatte? War es im Topic oder Payload?
Das ist eine gute Frage. Eigentlich genau zwischen beiden.
Nach dem Topic kam das problematische Byte (0x95), direkt danach die Payload.
Ich habe eben mal die Retained Messages des MQTT-Servers analysiert. Da wurde es scheinbar dem Topic zugeordnet.
Wenn ich mir alle Retained Topics mit MQTT_GetRetainedMessageTopicList() ausgegeben habe, wurde mir eines angezeigt, welches ich z.B. mit MQTT_GetRetainedMessage() nicht abfragen konnte. Da kam immer der Fehler „Kann Thema ‚…‘ für Retained Message nicht finden“. Selbst wenn ich das Topic aus den Hex-Daten inkl. dem Byte 0x95 am Ende generiert habe, hat er es nicht gefunden.
Im Debug des MQTT-IO sah es im Prinzip so aus:
topic_ebene1/topic_ebene2fehlerhaftes ByteWert
Wenn es dir hilft, kann ich dir einen kurzen IO-Dump zukommen lassen. Den Splitter konnte ich leider nicht debuggen.
Ne, das reicht als Antwort. Ich würde das Paket dann verwerfen und loggen, von wem dies gesendet wurde. Denn laut MQTT Specs sind nur UTF-8 im Topic erlaubt.
Ich habe mir die fehlerhaften Daten noch mal genauer angesehen.
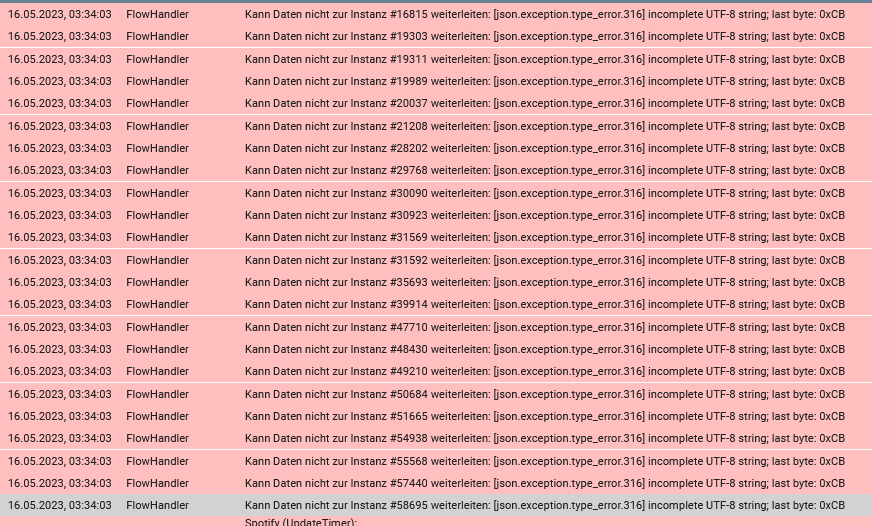
Streng genommen fehlten bei den korrupten Daten einige Hierarchieebenen des Topics. Stattdessen kam das problematische Byte direkt gefolgt von der Payload, welche aber wieder ok war.
Moin, möchte das Thema nochmal aufgreifen. Versuche gerade den Server Socket (des MQTT-Server) in der I/O-Instanz neu zu öffnen, kann sie aber nicht schließen da sich immer die Meldung öffnet : " Konnte Konfigurationsform nicht laden [json.exception.type_error.316] invalid UTF-8 byte at index 34: 0x74 (Code: -32700)„. Gleiches bei der Splitter Instanz „MQTT Server“.
Fehlermeldungen im Statusprotokoll: „Flow Handler Kann Daten nicht zur Instan #46777 weiterleiten: Vector too long“
Version:IP-Symcon 7.0, Windows (amd64), 10.11.2023, 5a3864aee916
Ursache könnte evtl. ein Shelly 2.5 sein der per Shelly2 eingebunden ist, da zwischendurch die Meldung"06.12.2023, 20:24:32 | FlowHandler | Kann Daten nicht zur Instanz #46444 weiterleiten: Malformed: Topic (30DB01002D30980B00293031002B303100) from 192.168.178.155:24453 contains non UTF-8 characters“ erscheint.
(Der Shelly2.5 läßt sich aber von seiner Weboberfläche bedienen).
Wie kann ich die I/O-Instanz wieder schließen ?
Wie kann ich den Fehler beheben ?
Gruß Gerd
Ein Neustart von Symcon sollte das Problem erstmal lösen und dann kannst du die Form öffnen. Trotzdem sendet der Shelly irgendwie nicht konforme Daten. Ich schaue mal ob ich das Formular besser absichern kann.
ja nach Symcon-Absturz heute Nacht u. Neustart konnte ich die Form wieder öffnen. Problem: „07.12.2023, 10:21:16 | FlowHandler | Kann Daten nicht zur Instanz #46444 weiterleiten: vector too long“ immer noch permanent vorhanden.
Gruß Gerd