Das glaube ich nicht.
Ich bin bestimmt hier nicht der einzige, der HW an IPS angeschlossen hat und nicht nur die Uhrzeit ausließt.
Wenn eine Verbindung von irgend einer I/O Instanz weg ist, muss sie nach lösen des Problems zeitnah „selber“ wieder hergestellt werden.
Ich denke auch nicht, das man das auf die lange Bank schieben sollte, das ist eigentlich eine grundlegende Funktion.
1 „Gefällt mir“
und um nicht nur zu meckern und konkret zu werden:
Octoprint: Plugin Rest-Call bei Startup einbauen, einen webhook in IPS der angesteuert wird, da drin ein Reconnect auf die Verbindung einbauen.
Aktiv muss das ggf. längere Zeit nicht erreichbare Gerät (wenn es der STandard ist ) sich melden, nicht passiv immer Pingen…
… ein IPS_ApplyChanges($ID_Instanz); reicht da schon aus,
aber das müsste auch automatisch gehen.
Und Octoprint war hier nur ein Beispiel, ich sehe das Problem auch bei vielen meiner Modbus I/O’s.
1 „Gefällt mir“
Aber genau das tut IPS doch schon in in viel kleinerem Intervall (am Anfang) als üblich.
Hier mal zur Visualisierung wie häufig das passiert:
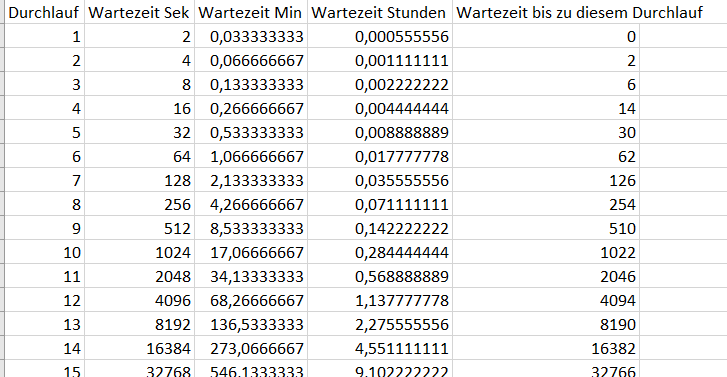
Das ist für ein Gerät das eigentlich „ON“ sein sollte schon sehr häufig und ich persönliche würde, wenn er beim 5 Durchlauf nicht wieder heile ist eh „eskalieren“ da ist mit einer Selbstheilung nicht mehr zu rechnen.
Bin da ganz deiner Meinung - das System sollte den Anwender unterstützen - nicht fordern! Aber der Vorschlag von @Paresy ist ganz gut.
Darüber sollten wir diskutieren!
Ich will ja zu Lösungen anregen. z.B. reicht ein Script mit diesem Inhalt im Eventcontroll verlinkt schon dafür, dass deine IO sich jede Minute reconnectet. Dazu muss doch nichts aufwändig zentral gebaut werden:
if($_IPS['SENDER'] == "TimerEvent")
{ IPS_SetScriptTimer($_IPS['SELF'], 0);
IPS_ApplyChanges($_IPS['INSTANCE']);}
IF ($_IPS['STATUS'] >= 400) {
IPS_SetScriptTimer($_IPS['SELF'], 60);
};
IF ($_IPS['STATUS'] == 102) {
IPS_SetScriptTimer($_IPS['SELF'], 0);
};
So sehe ich das auch. Das Verhalten an sich ist schon OK und macht Sinn. Problem ist aber das dies in der Community offensichtlich nicht bekannt ist.
Daher mein Vorschlag für einen „QuickFix“: Bei Instanzen welche davon betroffen sind den Zeitpunkt für den nächsten Versuch anzeigen. ggfl. noch etwa erklärenden Text dazu.
Die Instanz an sich ist bei Problem ja der erste Anlaufpunkt, damit ware das wissen über das Verhalten also recht schnell und einfach breit gestreut.
ym2c
bb
3 „Gefällt mir“
Den Zeitpunkt des nächsten Versuchs fände ich eine gute Erweiterung, da man ihn sonst nur durch Log durchforsten und selber hochrechnen sehen könnte.
Eine Option in der Instanz ob weiter „exponentiell“ weiter versucht werden soll die Verbindung neu aufzubauen oder ein fester Wert für den Reconnect fände ich sinnvoll.
Aber was sind denn eigentlich die Beweggründe, das nicht in kürzeren oder festen Intervallen zu machen? Ihr habt euch doch was dabei gedacht.
Verbraucht das zu viele Ressourcen oder warum sollte man dies nicht eh alle z.B. 1 min. versuchen?
Ich tippe mal: Übliches Verhalten für Retries in der IT-Welt. Egal ob Queues, Batches, Connections etc. überall wird in der Regel so vorgegangen, einziger Unterschied, da gibt es i.d.R. ein Max-Retries ab wo dann „von Hand“ eingegriffen werden muss, denn ewiges probieren löst selten Probleme.
Die Probleme werden ja auf der „Gegenseite“ gelöst und dann fände ich es halt schön, wenn IPS das auch zeitnah erkennt.
Es spricht ja nichts gegen einen exponentiellen Zeitzuwachs, aber der sollte dann auch nach oben gedeckelt werden.
Nur immer mit einem festen Wert neu versuchen ist auch nix, da würden dann vermutlich kurze Abbrüche unter gehen.
Deswegen kann man gerade bei PHP Modulen wie dem Octoprint das auch im Modul eleganter lösen.
Muss halt der Entwickler umsetzen oder jemand anderes.
Das Kodi Modul geht auch nicht davon aus das der Clientsocket permanent verbunden ist, weil der Player aus sein könnte. Verbindet sich aber innerhalb von x (einstellbar) Sekunden wenn der Play online geht.
Klar ist diese Lösung nur für Module so umsetzbar, wenn man es selbst nicht umsetzen will oder kann.
Anderseits kenne ich kein System, welches Symcon ab Werk unterstützt, wo keine dauerhafte Verbindung erforderlich ist. Aus der Sicht kann man auch das aktuelle Verhalten verstehen.
Michael
Bei Modulen kann ich das ja noch verstehen bzw. man kann dagegen etwas machen.
Es gibt aber viele Zustände, gerade bei KNX oder Modbus wo man sich einen zeitnahen Reconnect wünscht.
Keiner möchte, wenn das Internet mal 18 Std. ausfällt, weitere 9 Stunden auf einen autom. Reconnect warten oder die FritzBox über die Oberfläche manuell dazu anstoßen müssen.
Ich denke, das Problem oder der Wunsch ist jetzt klar und man hat ja angedeutet, da etwas dran zu verbessern, was ich sehr begrüßen würde. In der Zwischenzeit werde ich über ein Script zyklisch die wichtigsten Verbindungen prüfen und bei Bedarf einen Reconnect ausführen.
Für mich ist das ganze Thema hier aber schon ein deutlich Mehrwert gewesen, da ich mich schon lange darüber gewundert hatte, warum manche I/O Instanzen nach einem Verbindungsverlust anscheinlich nicht selber zurück kamen.
Denke das geht hier mehreren so …
Hi,
das erklärt in der Tat einiges und war mir auch nicht klar. Hab mich bei einem Update der CCU3 gewundert warum Symcon nicht mehr die Verbindung aufbaut, sobald diese da ist.
Wer mal ein Update der CCU3 gemacht hat, weiß das es mal locker 10-20 min dauern kann. Symcon würde dann 17-30 min warten… Das ist schon problematisch und nicht ersichtlich. Aber man könnte ein Modul schreiben, welches bestimmte i/o prüft und einen schnelleren reconnect erlaubt?
Viele Grüße
Das geht mit Boardmitteln uns braucht kein Modul.
Benutze das Event-Control um auf Veränderungen eines IO zu reagieren.
Michael
Wünschen würde ich mir wenn uns paresy mitteilen würde welche Instanzgruppen dieses exponentielle verhalten beim reconnect haben.
Weil es grad eben wieder passiert ist, frage ich mich ob es auch damit zusammenhängen kann:
Folgendes:
Ich habe zwei USB Dongles über einen Silex Remote USB Server angebunden. Das läuft schon seit Jahren so.
Es passiert aber immer mal wieder die zu den Dongles gehörenden Instanzen plötzlich „weg“ sind. Das äußert sich auf zweierlei Art.
- Entweder (selten) sind sie rot markiert, und der Konfigurator findet auch den Port nicht. Dann muß ich in der Silex Konsole neu verbinden. In diesem Zustand kann man auch nicht „Port Schließen“ → „Speichern“. Dann tauchen sie auch in IPS auf und ich kann neu verbinden.
- Oder aber (das passiert öfter) sind sie in IPS NICHT rot markiert. Es kommt aber trotzdem die Fehlermeldung die sinngemäße Fehlermeldung das der Port nicht angesprochen werden kann. In diesem Fall reicht es in der Instanz den Port zu schließen und wieder zu öffnen. Dann läuft wieder alles.
In Windows sind die Ports aber IMMER zu sehen und auch der Silex Monitor zeigt sie mir IMMER als verbunden an.-
Keine Ahnung ob es damit zu tun hat, aber das gleiche Verhalten hatte ich lange Zeit auch mit einem meiner zwei 1Wire Link USB welche direkt am IPS Rechner hängen. Auffallend: Der Zickige hatte auch immer mal CRC Probleme im 1 Wire Netz. Vor etwa 3 Monaten hab ich in dessen Netz aufgeräumt, und sieh da seitdem hatte ich nie wieder ein Problem mit dem USB Port bzw. der Instanz.
Das mal ein externes Gerät nicht will, das kann ich nicht IPS anlasten. Aber das es nach Problemsituationen scheinbar nicht immer auch wieder klaglos auf die Füße kommt erscheint mir schon auffällig.
Irgendeine Idee dazu ?
bb
Ist das die Antwort welche du suchst ?
Ich habe seit Jahren bei all meinen I/O-Instanzen das Problem. Jetzt verstehe ich das erste mal, warum das so ist. Was mir für den Anfang (oder generell) reichen würde: Probiert ein Script, Webfrontaktion, etc. die Schnittstelle zu erreichen, wird ebenfalls erneut probiert den Socket zu öffnen. Zudem würde ich eine Art ‚Keep-Alive‘-Watch begrüßen, der unabhängig von meiner Interaktion automatisiert einen Reconnect versucht, wenn nicht innerhalb X-Minuten irgenwas (definiertes) auf der Schnittstelle passiert ist.
1 „Gefällt mir“
Diese Erweiterung/Verbesserung ist übrigens mit der 7.0 dabei. Dort könnte ihr in den Ereignissen einstellen, welche Strategie standardmäßig verwendet wird und für spezifische Instanzen kann eine andere Strategie ausgewählt werden.
paresy