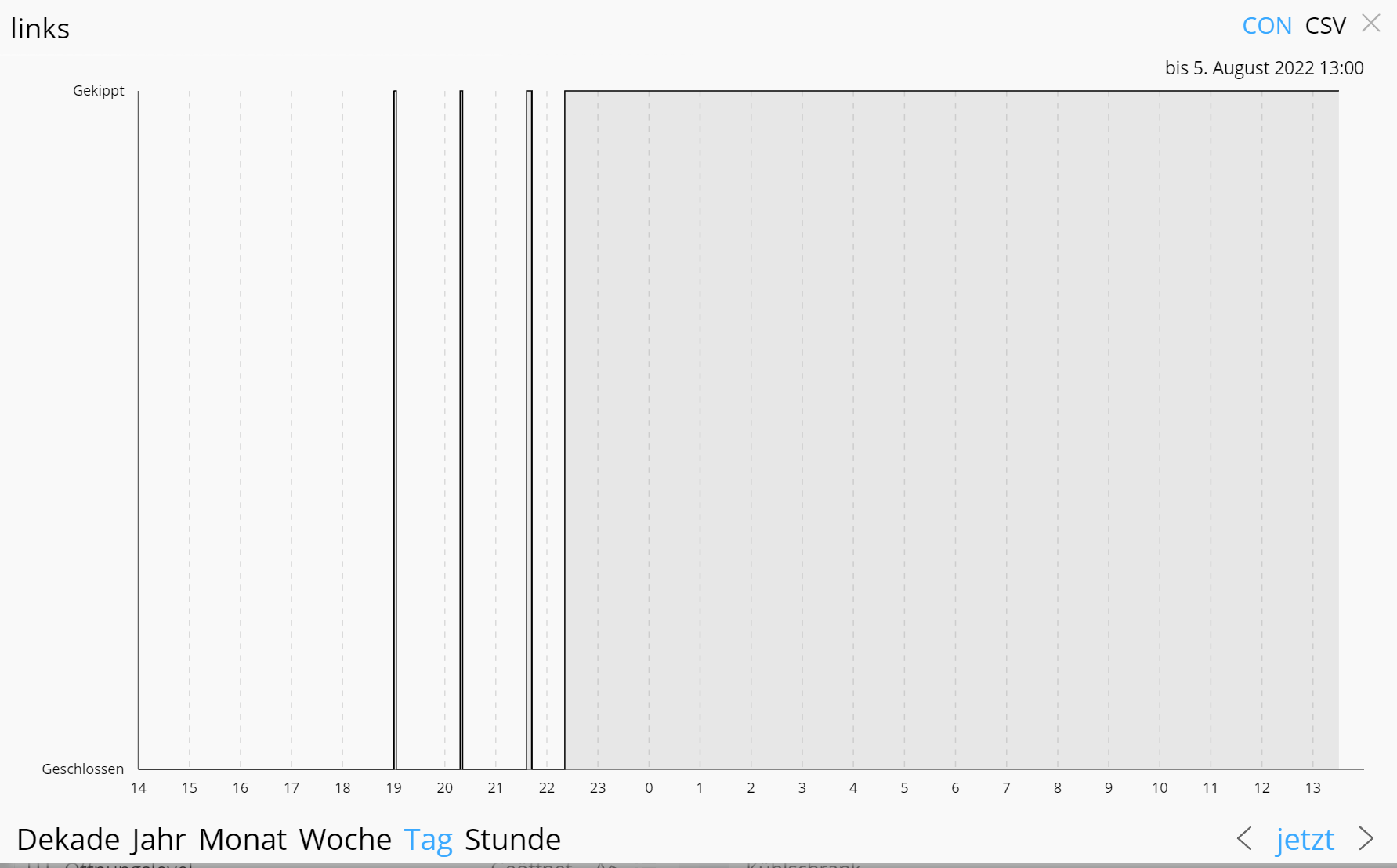
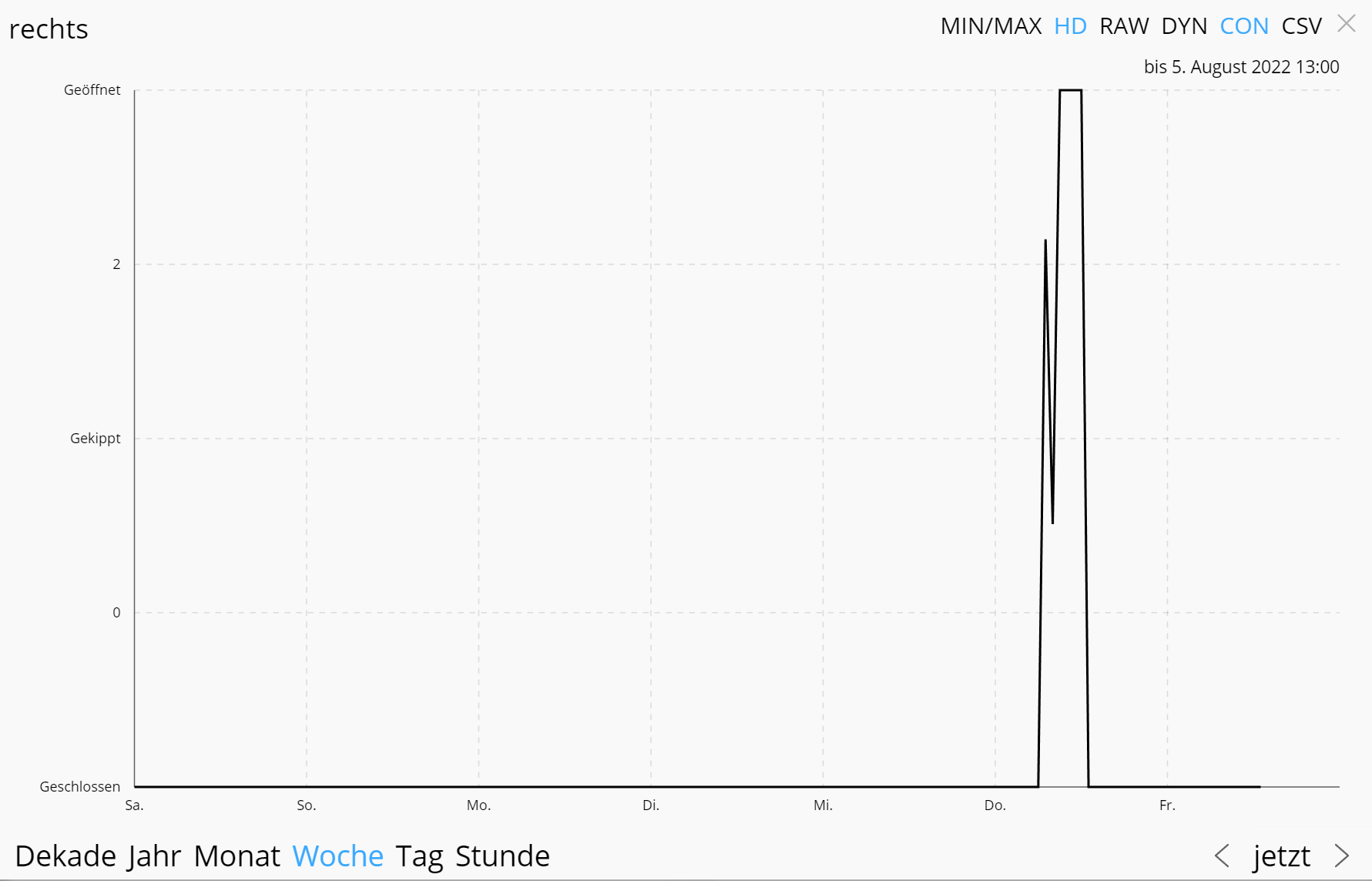
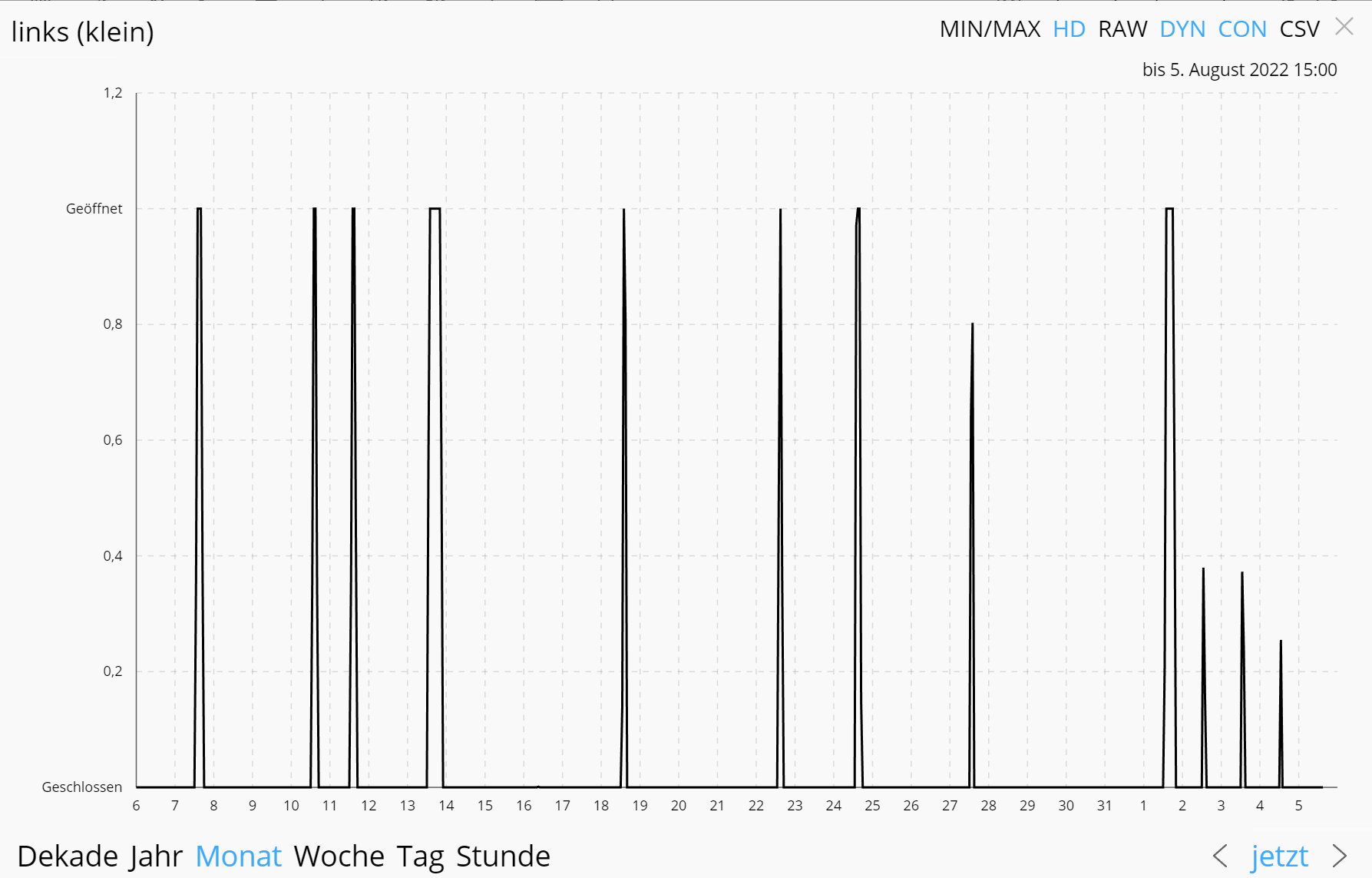
Wenn eine Variable genau zwei Aufzählungen hat, dann lässt sie sich binär darstellen und der Graph ist schick. Hier ein Beispiel für ein Fenster mit (geschlossen/gekippt):
Ich fände es super, wenn man in der Variablendefinition angeben könnte, dass es sich um „aufgezählte Werte“ handelt und dann der Graph wie bei Boolean dargestellt würde.
Nebenbei: die Klassifikation könnte auch beim Thema Aggregation helfen. Denn für Aufzählungen sollte auch eine Aggregation entfallen.
Wäre auch sehr dafür.
Problematisch ist es da nur, dass Aufzählung mit z.b. %d oder %f als Platzhalter ja Wertebereich darstellen können, welche z.b. nur andere Farben und Icons haben.
Aber das könnten man ja eventuell durch den Parameter Schrittweite erkennen??? Oder auch nicht?
Michael
PS: habe es nie kontrolliert, aber wird bei Integer Variablen eigentlich darauf geachtet das es bei Aggregation und auch in der Darstellung der Graphen keine Nachkommastellen gibt?
Das wollen wir definitiv auch nochmal umsetzen. Dafür könnte man entweder einen neuen Aggregationstyp „Keinen“ einführen oder dies automatisch auf Basis des Profils entscheiden (Assoziationen + Schrittweite = 0 bedeutet Enumeration, also keine Aggregation). All zu schnell kommt das aber wohl nicht, da wir dafür unter der Haube einiges anpassen müssen.
Ich wäre da für eine eindeutige Kennzeichnung. Sonst kommt es ja bei Profiländerungen zu ungewollten Reaggregationen bei allen nutzenden Variablen. Das fände ich nicht schön.
Finde ich gut. Je nachdem, welches Profil gesetzt ist, kann man ja „Standard“ oder „Keine“ als Standardauswahl setzen, wenn das Logging initial aktiviert wird.
So in der Art. Vielleicht wäre der Begriff „Statuswerte“ besser, also Standard/Statuswerte/Zähler. Dabei sollte sich die Darstellung des Graphen wie bei Boolean ändern:
Y-Achse ohne Zwischenschritte
Wegfall von Min/Max, HD, RAW und Dyn
Am Rande bemerkt:
bei Boolean Variablen gibt es momentan die Auswahlmöglichkeit der Aggregation Standard/Zähler. Hat die eine Auswirkung?
Bei Integer macht eine Aggregationauch Sinn. Sonst wären es viel zu viele Daten für eine Darstellung eines Graphen über einen großen Zeitraum.
Es dürfen nur keine Mittelwerte angenommen werden. Sondern die Aggregation muss den Zeitfaktor berücksichtigt. Dann verschwinden zwar 5 Minuten Fenster gekippt bei der Wochenansicht. Aber das ist dann ja okay.
Michael
Das sehe ich doch etwas anders. Wenn es sich um Statuswerte handelt, dann sollte da nichts gekürzt/ausgedünnt werden. Genauso wird es jetzt auch bei Boolean Variablen gehandhabt:
Auch wenn das Bild sehr schwarz ist so kann man doch immer noch erkennen, dass
das Fenster sehr oft geöffnet und geschlossen wurde
das Fenster während unseres Urlaubs geschlossen blieb
Bei einer Verdichtung sähe es sicherlich so aus, als ob das Fenster in einigen Wochen geöffnet und in anderen Wochen geschlossen gewesen wäre. Das wäre wertlos.
Das habe ich auch nicht gesagt.
Und ich meinte Integer nicht bool.
Dein Bild zeigt doch sogar eine Aggregations-Stufe
Ich meinte das eher darauf bezogen:
Wie du schreibst, dürfen dort keine Zwischenschritte in der Aggregation entstehen, dennoch muss für die Anzeige ja eine Art Mittelwerte angenommen werden. Entsprechend muss die Aggregationstufe den Zeitfaktor berücksichtigt.
Wenn dein Fenster jetzt in Summe pro Tag 23 Stunden zu und eine Stunde auf ist, dann verschwindet der ‚Strich‘ halt bei der Jahresansicht. Und in der Tagesansicht siehst du, dass du das Fenster viermal zu 15 Minuten offen hattest.
Und, solange man nicht ausdünnt, sind ja noch immer alle Rohdaten vorhanden.
Michael
Bei Boolean Variablen werden schon heute in den Graphen nur die Rohdaten verwendet. (Daher auch meine Frage an @Dr.Niels warum es dort überhaupt die Wahl Standard/Zähler gibt.) Genauso stelle ich mir das vor bei Integer Variablen, wenn sie Statusvariablen beinhalten.
Variablen, die Statuswerte beinhalten (true/false, Rot/Grün/Blau) kann man nicht sinnvoll verdichten, unabhängig davon ob es Boolean oder Integer sind. Damit lassen sie sich auch nicht ausdünnen, lediglich löschen.
Tatsächlich wird die Aggregation von Boolean-Variablen kontinuierlich aggregiert und kann auch sinnvoll verwendet werden. Eine Standard-Aggregation beinhaltet beispielsweise die Information wie oft ein Fenster im Laufe eines Tages etc. offen war. Bei einem Wert von 0,9 war ein Fenster also beispielsweise 90% der Zeit offen. Per Zähler kann man zählen, wie häufig etwas angeschaltet wurde, also die Summe der Wechsel von false auf true. Das ist schon recht speziell, kann aber sinnvoll verwendet werden
Verstehe, intern wird bei Boolean wie gehabt aggregiert. So dass man über AC _* Funktionen darauf zugreifen kann. Nur die Graphen unterstützen diesen - schon sehr speziellen - Fall nicht.
Aber bei mehr als zwei Zuständen macht dann wohl weder eine Durchschnittsbildung noch eine Zählung Sinn.