Hallo,
heute Morgen hat mir IPS ganz plötzlich mitgeteilt, dass es neu gestartet wäre.
Ich habe dann mal recherchiert, was da los war und habe mittlerweile das Archiv in Verdacht.
Das Log bricht irgendwann einfach ab, nachdem zuvor einige Minuten die Meldungen „Zu viele gleichzeitige Skripte. Verwerfe Ausführung…“ kamen. Im Log selbst war nichts auffälliges zu sehen. Keine Fehler, keine unnormalen oder häufigen Skriptaufrufe.
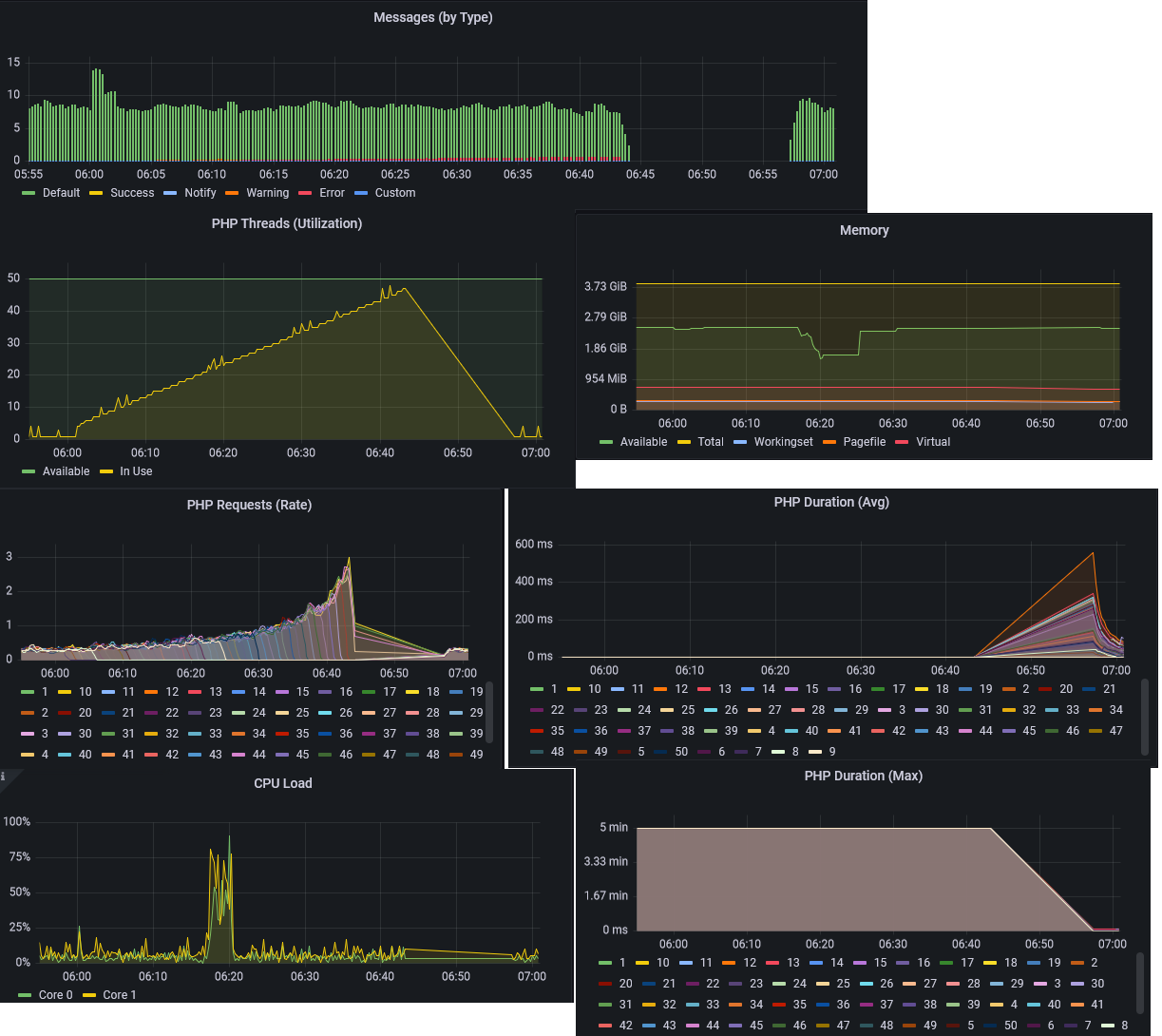
Also habe ich mir mal die Prometheus-Daten angesehen und festgestellt, dass kurz nach 6 Uhr plötzlich die Fehler kontinuierlich zugenommen haben, wovon ich aber dummerweise nichts im Log sehe. Außerdem ist zu sehen, dass die Anzahl genutzter Threads ab diesem Zeitpunkt anfängt, kontinuierlich zu steigen (ca. 1 Thread pro Minute). Das ging etwa über 40 Minuten so weiter, bis alle verfügbaren Threads ausgelastet waren. Nach ca. weiteren 15 Minuten hat sich der IPS-Dienst dann sang- und klanglos verabschiedet und ist neu gestartet.
Allein das wundert mich schon etwas, weil der Dienst bei mir noch nie nach einem Absturz von alleine wieder gestartet ist. Und es ist mir auch nich ganz klar, warum der Neustart letzten Endes erfolgte. Denn CPU-Ressourcen und RAM waren trotz belegter Threads nach wie vor vorhanden.
Naja, ich habe dann mal mit den sperrlichen Informationen weiter versucht, eine Ursache ausfindig zu machen. Crash Dumps gab es keine, das Log gab auch erst mal nichts her und die Metriken zeigten zwar den schleichenden Tod, aber keine Ursache.
Dann viel mir ein, dass ich minütlich die aktiven Threads und deren Laufzeit logge und habe mir die Daten mal aus dem Log-File gezogen. Und siehe da, jede Minute kamen immer wieder dieselben Skripts hinzu, welche offensichtlich endlos liefen. Die längsten Threads hatten 42 Minuten auf dem Buckel, wovon man komischer Weise aber nichts in den Metriken sieht (max. Laufzeit 5 Minuten). Die betroffenen Skripte selbst haben noch nie Probleme gemacht und laufen so seit Jahren vor sich hin. Allerdings gibt es eine Gemeinsamkeit der Skripte: alle greifen auf das Archiv zu und lesen geloggte Variablenwerte aus.
Und nun die Frage der Fragen:
Kann es sein, dass sich das Archiv unter bestimmten Umständen verklemmt und jegliche weitere Abfragen mittels AC_GetLoggedValues() und AC_GetAggregatedValues() blockiert und damit jedes Skript zum Hängen bringt, was diese Funktionen nutzt?
Das ist wirklich die einzige schlüssige Erklärung, die mir als Ursache einfällt. Und wenn dem so sein sollte, gibt es irgendeine Möglichkeit, dem zukünftig entgegen zu wirken?
Die zweite Frage, die sich mir stellt ist, warum der Dienst dann irgendwann scheinbar abgeschmiert und neu gestartet ist. In den seltenen Fällen, wo früher mal Skripte bei mir hängen geblieben sind, war es so, dass zwar irgendwann mangels freier Threads nichts mehr lief, aber der Dienst trotzdem noch halb tot im System hing und eher den ganzen Server in Mitleidenschaft gezogen hat, statt neu zu starten.
Hier noch ein paar Metriken, wo man den heutigen Absturz schön nachvollziehen kann.
IP-Symcon 6.3, Windows (amd64), 29.11.2022, 07e763adc3e2