Jup, weil downgrade is nicht.
Zu viele Test- und Spielsysteme.
Immer das neuste rauf, weil dann brauche ich mir die Stände nicht merken
Deswegen kann ich jetzt auch sagen (naja OSX hatte ich jetzt seit ca. 8 Monaten nicht mehr…) auf allen Systemen spinnen die Updates der Module.
Ich habe eben noch an einem anderen Modul gearbeitet.
Und jedesmal beim neu eintragen des Modul, ist mir IPS abgestützt
Michael, der nun mal etwas Freizeit genießt.
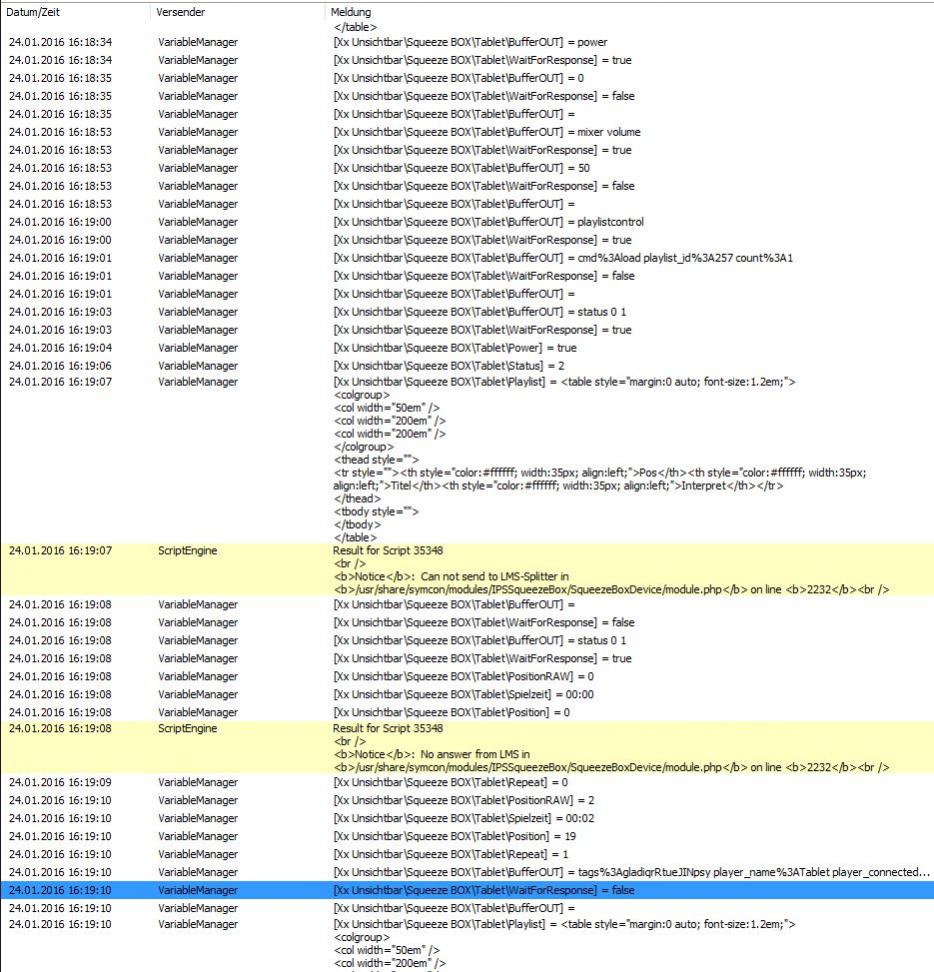
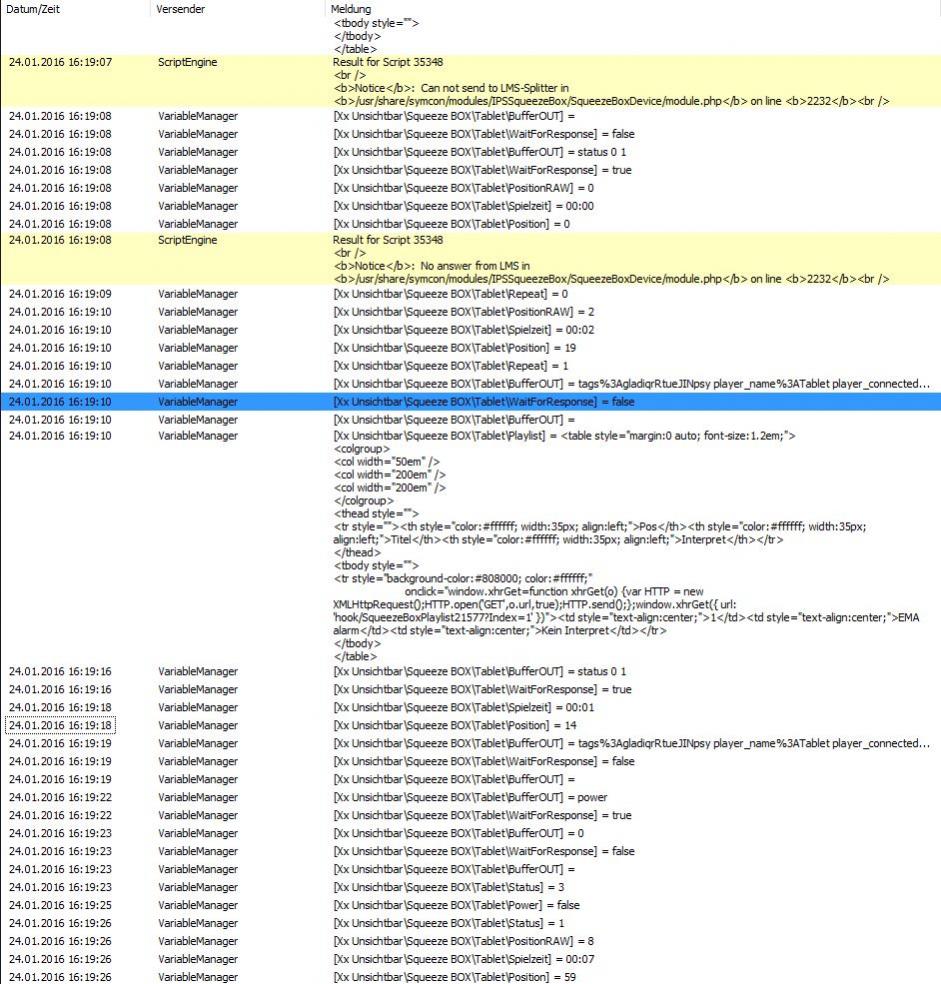
…sendet der Server im gleichen Datenpaket zweimal ‚newsong‘ und folgerichtig fordert das Modul beide Male Daten ab.
Irgendwas ist da merkwürdig, zumal es teilweise auch ‚ewig‘ (2 Sekunden) dauert bis die Antworten vom Server zu sehen sind.
Die „Can not send to LMS-Splitter … line 2232“ kommt immer noch manchmal und ich kann sie provozieren indem ich den Button im Dashboard direkt zweimal anklicke. Damit wird das Script dahinter zweimal gestartet und schickt zweimal
Die Fehlermeldung wird ja durch eine Semaphore geworfen
Ich sende Befehle im ‚blocking‘-Modus, damit ich zum einen euch die Rückmeldung per Rückgabewert der PHP-Funktion liefern kann. Und um die Ausführung des nächsten Befehls ( hier z.B. Play) so lange zu verzögern bis der vorherige Befehl komplett abgearbeitet ist. (Auch der ‚Kreis‘ im WebFront sollte sich so lange drehen, bis die Aktion bestätigt wurde.)
Wenn du nun natürlich das Script ‚quasi fast Zeitgleich‘ oder halt zu schnell mehrfach ausführst, muss eines dieser Scripte den ‚tod‘ sterben dass es nicht senden kann.
Eine Semaphore in deinem Script würde da erstmal abhilfe schaffen.
(Oder den Fehler einfach mit @LSQ_xyz unterdrücken)
Mich wundert nur warum bei dir der LMS so langsam ist. Laut IPS 2 Sekunden bis mal eine Antwort kommt, finde ich schon heftig.
Entweder ist eines der beiden Systemte bei dir extrem unter ‚Last‘, es ist ein Bug im Clientsocket oder im Datenaustausch von meinem Modul
Ich werde mal bei Gelegenheit das auf der Symbox testen. Mal sehen wie flott das Modul da läuft.
Mit den IPS_Sleep Zeiten habe ich etwas herum gespielt, sie sind deswegen so hoch. Mein Problem ist, dass der LMS nicht schnell genug antwortet und ich immer den Fehler in der Line 2232 bekomme.
Anbei auch mal ein LOG was beim Start des Scripts passiert. (Screenshots)
Was ich auch festgestellt habe ist, dass wenn alle Squeezeboxen aus sind, und ich bei einer Device „Request State“ anklicke, dauert es ca. 7-8 Sekunden bis die Daten kommen.
Ist das „normal“ ?? …oder liegt das an meinem Netzwerk aufbau? :p:)
Also das mit den Pausen im Skript dürfte gar keinen Unterschied machen.
Da alle Befehle für die Geräte so lange blockieren, bis entweder eine Antwort oder das 5 Sekunden Timeout kommt.
Sie werden also schön nacheinander abgearbeitet (außer man startet mehrere Scripte gleichzeitig ).
Die erfolgreiche Ausführung wird auch über einen Rückgabewert gemeldet!
Zusätzlich kann man die Fehlermeldung mit dem @ unterdrücken.
Es ändert aber nichts an den Problem dass hier irgendwas nicht passt.
7-8 Sekunden sind Welten für eine Antwort! Bei 5 Sekunden werfe auch den Timeout.
Bei Ralf fand ich schon die 2 Sekunden als zu viel.
Kann es sein das bei euch irgendwas am Limit läuft?
Das IPS z.B. auf dem Pi bei 100% CPU last ist, oder keine PHP-Threads mehr frei sind?
Oder gar das Hostsystem des LMS am Limit liegt?
Ich kann von diesen Problemen hier leider nichts nachstellen
Allerdings möchte ich den ganzen Part mit dem Datenaustausch noch mal überarbeiten, vielleicht ergibt sich ja was.
Immerhin ist dies das erste Modul mit Datenaustausch, weshald ich es auch als Testversion betitelt habe.
Michael
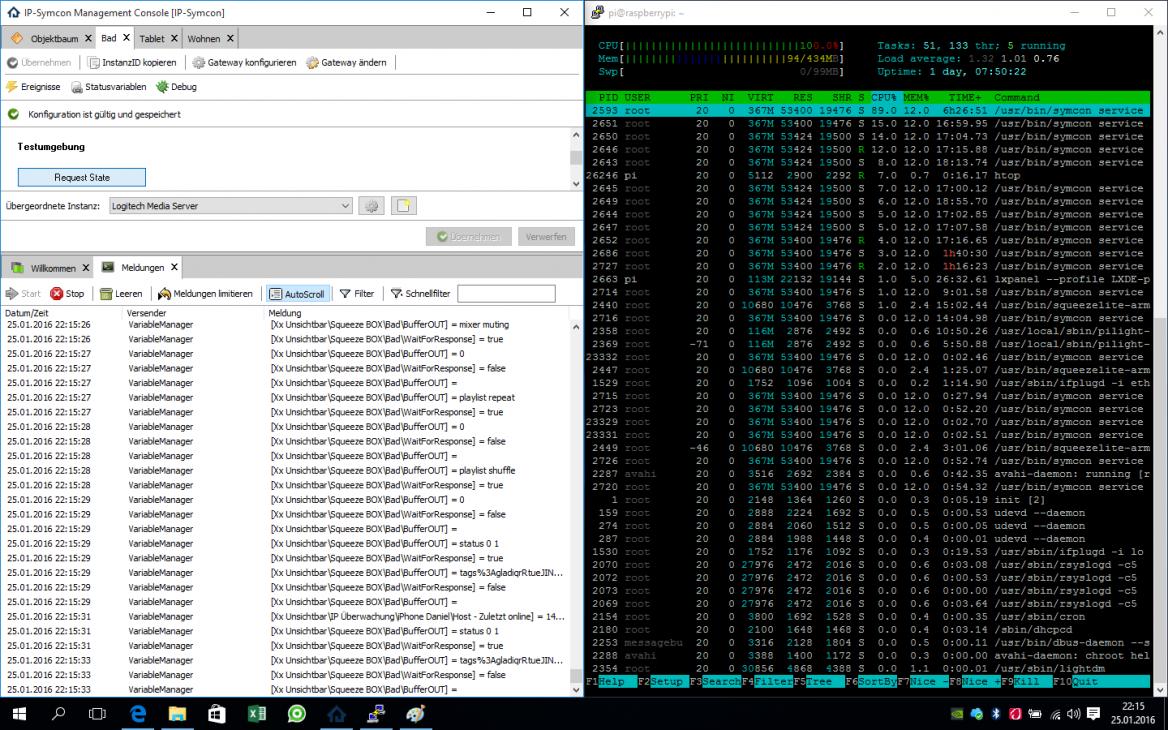
hab mir mal auf deinem Rat hin die CPU Auslastungen angesehen und da liegt auch das Problem.
Der LMS läuft ruhig auf meiner DS413j.
Aber der Raspberry mit der IPS rennt bis Anschlag, beim starten oder umschalten…
Der Sache förderlich ist es auch noch, das ich squeezelite auf selbigem installiert hab.
Aber auch beim steuern von anderen Boxen verhält sich die CPU genauso.
Der Raspberry ist ein Pi2, dachte eigentlich das dieser ausreichen sollte.
Im Ruhezustand rennt er jetzt bei 18% - ohne Musik.
Bei mir liegt es definitiv nicht an der Auslastung vom LMS (QNAP) oder dem PI2B, beide machen „eher nix“. Ich habe leider auch immer wieder Probleme mit den „zu schnellen Reaktionen auf scheinbare Timeouts“.
Aktuell ist mein Player im Büro
27.01.2016 18:43:12*| ScriptEngine*| Result for Script 52428
<br />
<b>Notice</b>: Device not connected in <b>/usr/share/symcon/modules/IPSSqueezeBox/SqueezeBoxDevice/module.php</b> on line <b>2232</b><br />
aber ich höre den Sound :), sogar eingeschaltet über IPS auf dem PI2.
Manuell auf True setzen unterbindet die Fehlermeldungen für eine Weile, irgendwann ist der Player wieder „wech“.
Bei 7 Playern und zweimal IPS, die den LMS befragen, mag es auch an „Überschneidungen“ liegen. Aber die „Stabilität“ des Moduls hält mich noch von der kompletten Umstellung der Squeezeboxen ab.
Update:
Vielleicht solltest du im „Connected Test“ berücksichtigen, ob das Modul aktuell mit dem Player kommuniziert. Der „Mecker“ kommt ja, weil die Playlist aktualisiert werden soll, das Modul aber meint, der Player wäre aus.
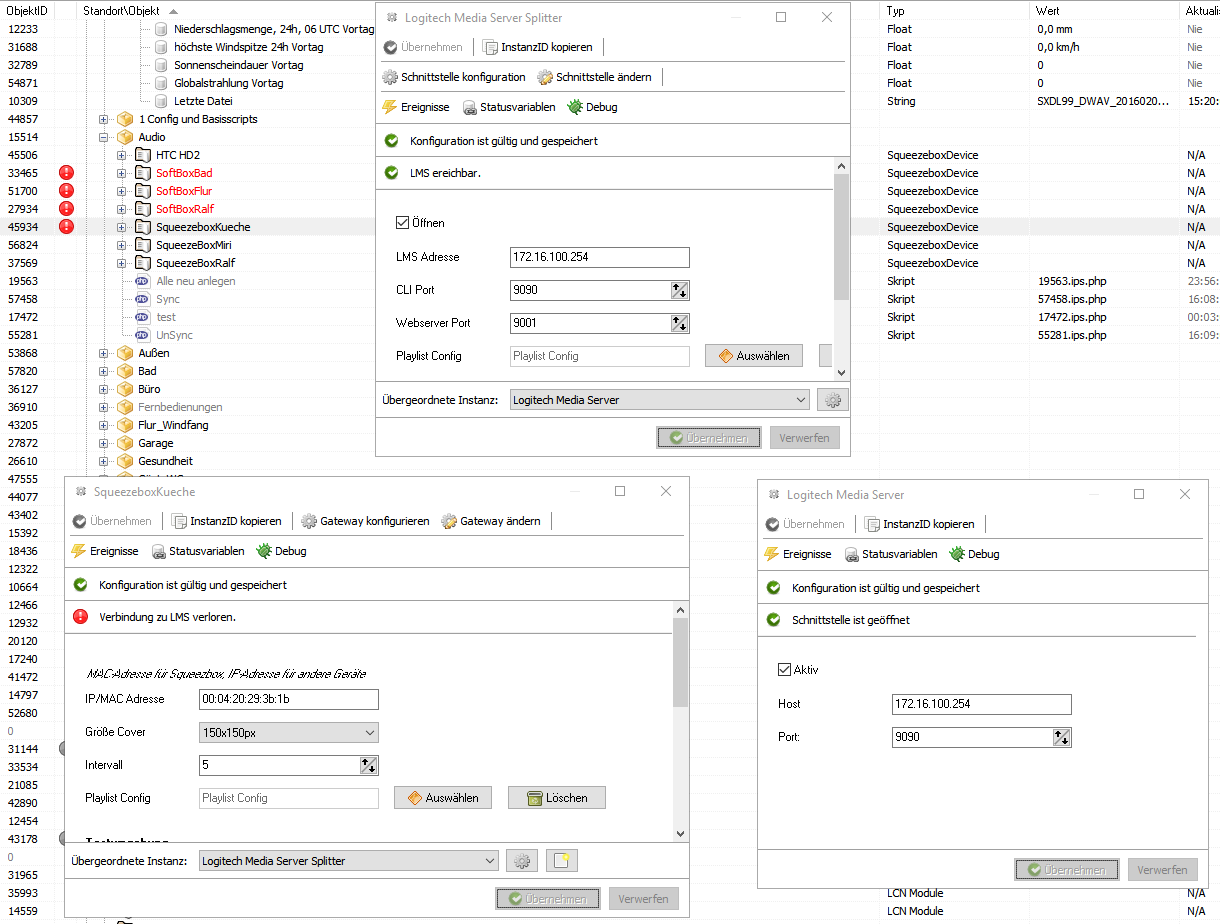
Ich mache ja gar keinen Test in dem Sinne. Ich frage einmal (beim Verbindungsaufbau = IPS Neustart oder Übernehmen anklicken des Splitters) den Server ab welche Geräte er kennt. Dann lasse ich jedes Device-Instanz noch beim Server anfragen ob er online ist. Ende.
Danach reagiere ich nur noch auf die Events vom Server.
Das kann ein ‚MAC client disconnect‘, ‚MAC client new‘ oder ‚MAC client reconnect‘ sein.
Oder aber auch ein ‚MAC connected 1‘ bzw. ‚MAC connected 0‘.
Ansonsten fasse ich diese Variable gar nicht mehr an.
Die Frage ist also warum ist der MediaServer der Meinung dein Player ist aus ?
Wenn du das nachstellen kannst…
z.B. Ein Debug des Socket, wenn die Variable ‚Connected‘ auf false springt, könnte ich mal versuchen nachzuvollziehen was da passiert.
Allerdings bin ich ja eh noch nicht zufrieden mit der Auswertung des Protokolls und schließe da somit auch keinen Fehler bei mir aus.
Eventuell werde ich das ganze noch mal neu ‚erfinden‘ und dann eine bessere Trennung zwischen den Events und den Antworten des Servers einbauen.
Dann kommt man dem vielleicht eher auf die Spur
Ich versuche Morgenabend oder spätestens am WE mal tiefer zu analysieren.
Das Protokoll ist ja nicht wirklich auf mehrere „Externe Frager“ ausgelegt, es wird zwar ein dedizierter Client angefragt, aber der antwortet „an alle die mitlesen“, es gibt ja kein Ziel für die Antwort:
Eine Frage wäre z.B. wie gehst du mit einer Response um, die du nicht selber requested (WaitForResponse) hast, weil meine Scripte aus der V3.4 die Anfrage geschickt haben.
Es kommen bei mir halt ähnliche Anfragen von beiden IPS Servern, somit gibt es eventuell sehr zeitnah gleiche Antworten vom LMS.
Ergänzend nutzen wir teilweise auch Apps auf den Mobiltelefonen/Tablets um die Playlist zu wechseln oder die Lautstärke zu ändern. Auch die Apps schicken natürlich vergleichbare Anfragen and den LMS und werten Antworten aus.
Update online welches einige Verbesserungen in Sachen IPS-Neustart bzw. verlorenen LMS-Verbindungen betrifft.
Also dann macht dein LMS ‚Mist‘.
Ich habe eben auch mit 4.0 und 3.4 parallel getestet.
Der Server sendet nur an den Fragenden die Antwort zurück.
Lediglich die Events werden an ‚alle‘ verbundenen CLI-Clients gesendet.
Aktuell unterscheide ich dazwischen nicht, es landet alles in einem ‚Topf‘.
Dies ist zusammen mit dem allgemeinen Datenaustausch ‚ohne Warteschlange‘ mein MK 2 für Ostern
(= wenn ich Zeit habe)