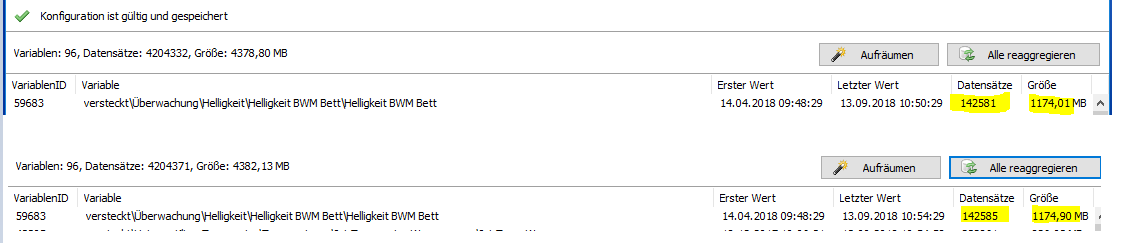
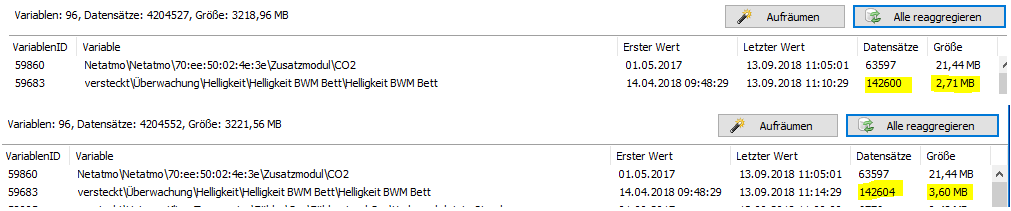
Ich bekomme die Meldungen „Writing negative record size for variable…“ auch ständig und muss alle paar Tage mein Archiv reaggregieren, weil mehrere Variablen negative Größen haben (siehe Screenshot).
Es handelt sich eigentlich immer um die gleichen Variablen, welche sehr häufig geändert werden.
Die von Dr. Niels erwähnten Meldungen finde ich allerdings nirgendwo in den Log-Files.
Im Screenshot sieht man einmal einen Auszug vor dem Reaggregieren mit teils negativen Werten.
Dann kommt ein Screenshot nach dem Reaggregieren und dann noch mal einer, nach dem ich ein weiteres Mal reaggregiert habe.
Der blau markierte Eintrag ist immer die gleiche Variable. Erst negativ, dann extrem groß, dann realistisch.
@Niels Ich habe mal einen Auszug meines Logs beigefügt.
Die Variable 35692 wird in der dritten Zeile normal gespeichert :
06.09.2018 14:09:40 | 35692 | DEBUG | KernelMT | Nachricht VM_UPDATE für ID 35692 dauerte 56 ms (Modul: InstanceManager)
In der 4 letzten Zeile kommt dann die erste negativ Meldung
06.09.2018 14:33:23 | 14817 | DEBUG | Archive Control | Writing negative record size for variable 35692
Vielleicht findest Du ja einen Hinweis in den Logmeldungen dazwischen (Die ich leider nicht hochladen kann weil die Datei immer noch zu gross ist) negativelog.txt - Google Drive
Update einige Tage später:
Nun 140124 Datenpunkte (+4986) und angeblicher Speicherbedarf gestiegen auf 683 MB.
Zum Vergleich der Zustand direkt nach Aggregation: 134775 Datenpunkte und 2,5 MB.
Der Zuwachs an Speicherbedarf ist nun gestiegen auf +136kB pro neuem Datenpunkt. Der angebliche Speicherbedarf !pro Datenpunkt! wächst also immer schneller, je mehr Datenpunkte es gibt. Da würde ich mal ansetzen, wie der Speicherbedarf pro Datenpunkt berechnet wird. Vielleicht wird da eine Variable nicht zurückgesetzt und wird immer weiter aufaddiert.
Hallo
In einem anderen Thread hatten wir ja schon mal darüber diskutiert.
Ich bin immer noch der Meinung das es durch irgendwelche race conditions passieren muß. Hier sind vorzugsweise jene Variablen betroffen welche in Scripten geschrieben werden welche zum gleichen Zeitpunkt durch eine dritte Variable getriggert werden.
Bsp: Variable a triggert durch Änderung Script „A“ und Script „B“. Die in diesen Scripten berechneten Variablen sind vorwiegend betroffen.
Allerdings hab ich hier auch zwei böse Variabeln von 1Wire Temp-Fühlern welche überhaupt nie durch ein Script schreibend angefasst werden. Am Bus hängen noch so etwa 20 andere 1Wire Fühler, bei denen schaut es gut aus.
Die angesprochenn Meldungen sind mir bis dato noch nicht begegnet.
Ich vermute da läuft wirklich die Variable für den Speicherbedarf pro Datenpunkt hoch und wird negativ, siehe Threadtitel. Die negative Gesamtgröße ist dann nur ein Folgeeffekt.
Ich starte nun mal IPS neu und schaue, ob das (angeblichen) Speicherbedarf pro Datenpunkt verändert.
edit: Nach Neustart der IPS-Task nun +196kB pro Datenpunkt, also kleine Änderung aber weit weg vom korrekten Wert (ca. 20 Byte).
Ich aggregiere nun mal diese eine Variable neu (nur diese).
Interessantes Ergebnis: der berechnete Gesamtspeicherbedarf ist nun korrekt, aber der falsche hohe Zuwachs pro Datenpunkt bleibt. Aktuell +222kB pro Datenpunkt.
Ich wiederhole das Experiment und reaggregiere nun alle Variablen, um zu schauen, ob die Entwicklung des Speicherbedarfs dann anders ist.
Ergebnis: Zuwachs an Speicherbedarf pro Datenpunkt beträgt nun +228kB, der Wert kennt nur ein Richtung: er steigt.
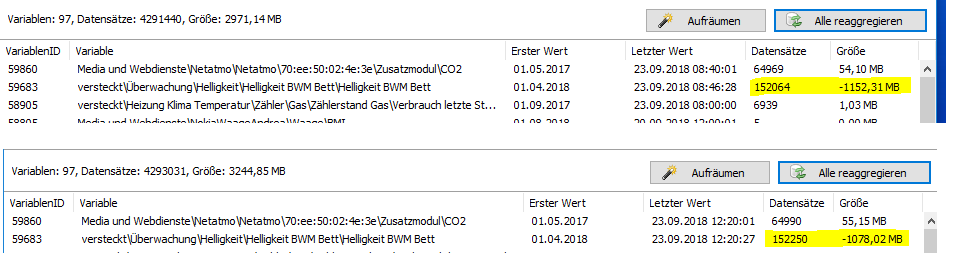
Inzwischen ist der berechnete Speicherbedarf in’s Negative gelaufen, hier zwei Schnappschüsse von heute.
Dazwischen liegen +186 Datenpunkte, Speicherbedarf pro Datenpunkt nun 409kB
Es kostet mich einige Zeit täglich die Variablen neu zu aggregieren die eine negative Größe haben. Wäre es nicht möglich das einmal am Tag zu automatisieren ?
Ich bin weiterhin am Suchen, aber leider finde ich keine Stelle, an der dieser Zuwachs kommen könnte… Bis dahin kann ich dir aber eine undokumentierte Funktion anbieten: AC_ReAggregateVariable(ArchiveID, VariableID) reaggregiert die entsprechende Variable. Wie üblich mit undokumentierten Funktionen, kannst du dich nicht auf Dauer auf diese Schnittstelle verlassen, aber bis das eigentliche Problem gelöst ist, sollte das passen.
Warum machst du das immer ? Da ist doch nur in der Berechnung der größe irgendwo der Wurm drin. Ich habe hier viele Variablen mit unmöglichen Größenangaben das stört doch nicht weiter.
Ich hatte mit der Einführung von 5.0 das Problem das bestimmte Charts nicht mehr angezeigt wurden. Durch das erneute aggregieren wurde der Fehler behoben.
Bisher fehlt uns immer noch ein reproduzierbares Szenario. Falls es jemand hinbekommt, eine Abfolge an Operationen zu ermitteln, die jedes mal zu falschen Größen führt, dann wäre uns bei der Fehlersuche sehr geholfen.
Also bei mir ist’s ein Effekt, der bei Variablen mit vielen Datenpunkten (Werten) auftritt, und das erst viele Datenpunkte (Werte) nach der Aggregation. Der Speicherbedarf für jeden weiteren Wert läuft dann immer weiter hoch auf komplett falsche Werte(siehe meine Posts oben) was in Folge zu falschen Werten für den Speicherbedarf der Variable insgesamt führt.
Anders gesagt: der Speicherbedarf steigt bei neuen Werten nicht linear mit der Anzahl, sondern nichtlinear, immer schneller.
Das müsste man doch eigentlich im Code einkreisen könne, wo/wie bei einem zusätzlichen geloggten Wert der zugehörige Speicherbedarf ermittelt wird. mMn wird da eine interne Variable nicht zurückgesetzt und zählt immer weiter hoch.
Wenn du Debugwerte ausgeben kannst/willst, sag Bescheid und ich lass das hier laufen.
Ich denke auch, dass es mit der Menge und/oder Häufigkeit an Datenpunkten zusammenhängt. Das Problem tritt bei mir nur bei Variablen auf, die sich sehr schnell/oft ändern - z.B. Windgeschwindigkeit, Helligkeit (draußen), stark frequentierte Bewegungsmelder etc.
Vielleicht kann man das ja mit einem entsprechenden Script simulieren, indem man jede Sekunde oder öfter Zufallswerte schreibt und die Variable loggt.
Hallo
Gleiches wie Slummi hab ich schon vor langer Zeit festgestellt und reportet. Gab aber kein Feedback.
Auch bei mir sind es vorwiegend Variablen welche mehr oder weniger parallel geändert werden.
(ein Trigger startet zur gleichen Zeit mehrere Scripts welche dann ihrerseits Variablen schreiben)
Scheint also eine Race-Condition oder sowas zu sein.
Bei denen habe ich den Effekt innerhalb weniger Stunden.
Variabeln welche asynchron geändert werden haben das Problem nicht oder nur sehr selten.